Mudé mi blog a
github para empezar una nueva etapa. http://santiagombv.github.io/
11 de enero de 2016
13 de septiembre de 2012
Modelos Aditivos Generalizados y Selección II. Un modelo "sencillo".
Si, ya sé
que demoro mucho entre post y post, pero bue...
Supongamos
que queremos realizar un spline cúbico donde la adecuación (fitness) es el
número de polinarios exportados por una orquídea, y el rasgo
fenotípico es el número total de flores producidas por la planta. Utilizaremos el paquete mgcv
de Simon Wood.
library(mgcv)
fit<-gam(pol.exp ~ s(flores, bs="cr"),
data=datos, family=poisson)
El término s()
simplemente indica que el número de polinarios exportados depende de un spline
del número de flores. La sección bs="cr" indica que utilizaremos es
un cubic spline. Lo hacemos por "tradición", ya que es el método más
empleado en ecología evolutiva, pero existen muchas opciones disponibles (ver
en ?smooth.terms).
La familia Poisson parece la elección natural, ya que la variable respuesta es
un conteo.
Observemos
el resultado del modelo:
summary(fit1) #(resumido)
Family: poisson
Link function: log
Parametric coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept)
2.3808 0.0339 70.24
<2e-16 ***
Approximate significance of smooth terms:
edf Ref.df Chi.sq p-value
s(flores) 8.372 8.805
703.8 <2e-16 ***
R-sq.(adj) =
0.766 Deviance explained = 79.3%
UBRE score = 1.1506 Scale est. = 1 n = 119
- El modelo
se divide en dos partes: la paramétrica (en este caso es solamente un
intercepto) y el smooth.
- El smoth
es significativo, así que no es una línea horizontal (ni tiene intervalos
de confianza tan grandes que puedan incluir una recta horizontal en su interior).
- La
complejidad de la curva ajustada es reflejada por los effective degrees of
freedom (efd, como comparación si fuera una línea recta serían cercanos a uno).
- El grado
de complejidad de la curva se calculó automáticamente minimizando el parámetro
UBRE (en caso de no conocerse el parámetro de escala, usará GCV aunque hay
otros métodos posibles). Si por curiosidad queremos conocer el valor de lambda,
está almacenado en fit1$sp.
Para
examinar la bondad de ajuste del modelo utilizaremos gam.check
gam.check(fit1)#(resumido)
...
Basis dimension (k) checking results. Low
p-value (k-index<1) may
indicate that k is too low, especially if
edf is close to k'.
k' edf k-index p-value
s(flores) 9.00 8.37 1.04
0.62

La parte
escrita nos indica (entre otras cosas) que el máximo número posible de grados de libertad de
nuestro modelo es suficiente(por defecto son 10). Este número puede manipularse,
por ejemplo: s(flores, bs="cr", k=20.
En el
análisis gráfico deberíamos esperar observar normalidad en los dos gráficos de
la izquierda, falta de patrón en el de la derecha arriba, y ajuste a una línea
recta en el de la derecha abajo. Para nuestros datos, lo más notable es la sobredispersión observada en el gráfico de residuals vs. linear predictors
("forma de trompeta" la nube de puntos se ensancha hacia la derecha). Probaremos un modelo quasi.
fit2<-gam(pol.exp~s(flores,
bs="cr"), data=datos, family=quasipoisson)
summary(fit2) #resumido
Family: quasipoisson
Link function: log
Parametric coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept)
2.40844 0.04673 51.54
<2e-16 ***
Approximate significance of smooth terms:
edf Ref.df F p-value
s(flores) 5.074 5.94 58.32
<2e-16 ***
R-sq.(adj) =
0.768 Deviance explained = 78.1%
GCV score =
2.336 Scale est. = 2.2168 n = 119
gam.check(fit2) #(sólo gráficos)

Observamos en Scale est. que el parámetro de escala es mayor a 2, por lo que los supuestos de la
relación media-varianza de un modelo Poisson no se cumplen adecuadamente
(debería estar cercano a 1). El spline ajustado es, además, más sencillo, según
observamos en sus edf. El gráfico de residuals vs. linear
predictors indica que la mayor parte de la sobredispersión ha sido removida.
Finalmente,
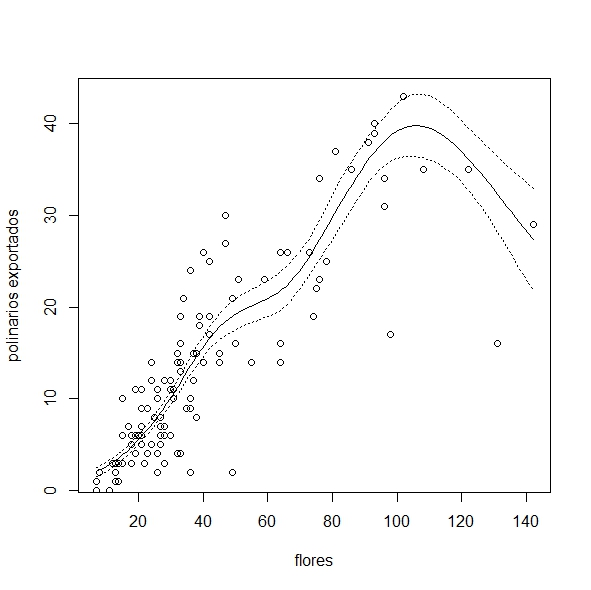
nos interesa graficar el resultado. El gráfico sencillo, lamentablemente, tiene la variable respuesta en la escala del predictor lineal y
para colmo estandarizada.
plot(fit2)

Algo mejor podemos lograr con la vieja (y tediosa) trampa de graficar los predichos
#Calculamos
una "nueva" variable X
MIN<-
min(datos$flores, na.rm=T)
MAX<-
max(datos$flores, na.rm=T)
newX <- seq(from=MIN, to=MAX ,
length=100)
#Calculamos una nueva Y con sus errores
newY <- predict (fit2, newdata=list(flores=newX),
se.fit=TRUE,
type="response") #"response" predice en la escala original
Yhat <- newY$fit #valor
predicho
Yup <- newY$fit + newY$se.fit #límite
superior
Ydown <- newY$fit - newY$se.fit #límite inferior
#graficamos
plot(newX, Yhat, type="l",
xlab="flores", ylab="polinarios exportados",
ylim=c(min(Ydown), max(Yup)))
#agregamos los intervalos de confianza
lines(newX, Yup, lty=3)
lines(newX, Ydown, lty=3)
#agregamos los puntos observados
points(datos$flores,
datos$pol.exp)
!!!!
10 de junio de 2012
Modelos Aditivos Generalizados y Selección I. Para entender al spline cúbico...
La
superficie de selección es una función que relaciona la adecuación (fitness)
con uno o varios rasgos fenotípicos. Habitualmente se utiliza la fórmula de
Lande y Arnold (1) para describirla, y clasificarla en direccional,
estabilizadora, disruptiva o una combinación de ellas. Sin embargo, nada impide
que la superficie de selección tome distintas formas. Para evitar
los supuestos sobre la forma de la selección (y ciertos problemillas de la fórmula de
Lande y Arnold), Dolph Schluter propuso (2) utilizar un método no
paramétrico, de forma tal que
donde w es
la adecuación, z es un rasgo, e es el error y f sólo afirma que existe una
función entre w y z. Específicamente, propone además utilizar un cubic spline
para describir esa forma y máxima verosimilitud penalizada para hallar la
complejidad óptima de ese spline.
Vamos por
partes... El spline es construido siguiendo ciertos pasos:

En A tenemos la nube de puntos original,
en B la nube se divide en
"ventanas" más pequeñas, en C
una regresión cúbica es ajustada en cada ventana, finalmente en D, estas regresiones cúbicas son
"empalmadas".
Como puede
suponerse, cuanto más pequeñas son esas ventanas, más "rugosa" es la
superficie. Sin embargo, elegir la cantidad óptima de ventanas no es tarea
fácil. En vez de eso, se utiliza un atajo utilizando penalización. El spline
óptimo es aquel que minimiza la cantidad:

La segunda
parte de la ecuación es la penalización, la cual es controlada por el parámetro
lambda. Podemos ver el efecto de la penalización.

En A la penalización es baja, y el spline intenta
cruzar todos los puntos, en B la
penalización es alta y el spline se aproxima a una línea recta para evitar la
rugosidad. Esta penalización se maneja sencillamente cambiando los valores de
lambda. Valores cercanos a 0 corresponden a la situación A, valores altos a la
B. Elegir el mejor spline queda entonces reducido a buscar la mejor lambda, para lo cual se utiliza validación cruzada. Uno de esos métodos (generalized cross
validation, GCV), consiste en elegir un rango de valores de lambda y para cada
uno de ellos calcular el valor de la ecuación 2, siendo el óptimo aquel que
minimice su valor. El pequeño detalle es que los residuos no son calculados de
la forma acostumbrada. Para estimarlos quito una observación del set de datos,
ajusto el spline con las restantes, predigo el valor de la observación faltante
y calculo el residuo como la diferencia entre el predicho y la observación
faltante. Luego quito otra observación.... y así hasta hacerlo con cada uno de
los datos.
Por cierto,
escribo cómo hacerlo en R en otro post jeje.
1- Lande R. y Arnold S.J. (1983).
The measurement of selection on
correlated characters. Evolution 37:
1210–1226.
2- Schluter D. (1988). Estimating the form of natural selection on a
quantitative trait. Evolution 42:
849–861.
Suscribirse a:
Entradas (Atom)
